Motivation
Analysis preservation is an important concept in data analyses. Its main advantages are:
- Keep track of your work and help you share it
- Spare you a consequent amount of time when it comes to redo a complete or partial analysis
- Reduce artificial mistakes inherent to the human condition of the data analyst
The two first points were partially developed in the tutorial Analysis preservation using Snakemake. The purpose of the present tutorial is to offer a solution to efficiently handle the results produced in your analysis. The main outcome is a working environment able to fill various templates in an automatic way.
In this tutorial, we will analyse three different examples:
- One template to produce different text files.
- Fill a C++ header file with a namespace containing various constants without your keyboard
- Fill a Latex table without a single number typed manually
Credit
On the idea of Luca Pescatore, we used automated templates to handle the results of the analysis. The idea was to spare some time in the filling of Latex tables but also to be able to rerun the main results rapidly and present them in an efficient way. The main conception of the automation was provided by Luca and the credit goes to him for the class Outfiles used throughout the tutorial.
Index
- Requirements
- Installation
- The working environment
- Dictionaries (storage)
- Templates
- Examples: One template two text files
- Examples: Automated C++ headers containing namespaces
- Examples: Latex automated tables
Requirements
This tutorial is meant to be used with python2. I assume you will be working from a shell terminal. I also expect you to be familiar with the basics of the bash language.
Installation
To make this tutorial slightly more interesting, I prepared a github project you can download via:
git clone https://github.com/mstamenk/automated-templates.git
Once the repertory downloaded, go into the root and source the shell script setup.sh the environment.
cd automated-templates/
source setup.sh
The last command will basically set the paths relative to the various folders in the tutorial so we can access them from any programming languages. It will also explicit the $PYTHONPATH so we can use modules and it will create two alias: clean and db. The first one is to remove the .txt, .tex and .hpp files we will produce and the second one will be detailed at the end of the tutorial.
The working environment
The architecture of the working environment is as follows:
# Architecture of the project
|--automated-templates
|--setup.sh # Set the environment
|--generate.py # Fill the dict.
|--process.py # Fill templates
|--database # Store dict.
|--outfiles_list.txt # Dict. list
|--db.pkl # Database dict.
|--routines
|--Analysis.py # Project management
|--create_db.py # Create and store dict.
|--tables # Store final outputs
|--templates
|--exmaple1.tmp # Various templates
|--exmaple2.tmp
|--exmaple3.tmp
The environment is separated into three main parts:
- Database: the point is to store the results produced in the analysis and I choose to use the very friendly python dictionary, abbreviated
dictwith the extension.pkl. - Tables - Templates: the purpose is to store the templates (extension
.tmpand the various output of these templates, in this tutorial mainly and the various output of these templates, in this tutorial mainly.txt,.hppand.texextensions. - Routines: if you already followed another tutorial on this site, you should be familiar with this part. I mainly use it to manage the project. This is the heart of the architecture and it contains the locations of all the folders, various class definitions and methods useful to manage the project.
Let's now consider you produced various results in your analysis (this part is represented by the script generate.py in this tutorial). This tutorial is meant to show you how to store these results in a python dictionary format and then to use the dictionaries to fill templates.
Dictionaries
Storing python dictionaries is extremely easy thanks to the module pickle. In order to store a dictionary, we first need to define where to store it.
In the database folder, create a file named db.pkl containing the following two lines:
# database/db.pkl
(dp0
.
This file will gently be interpreted by the pickle module as a python dictionary and the module will handle the writing and reading. We will just handle the python format which we are familiar with. In this tutorial, every definitions happen in the routines/Analysis.py folder. We need the following lines:
# routines/Analysis.py
import pickle
db = pickle.load(open(loc.DATABASE+'db.pkl'))
def dump(dataB,name):
pickle.dump(dataB,open(loc.DATABASE+name,'w'))
def dumpAll():
dump(db,'db.pkl')
That's it! The db object is now an empty python dictionary where you can store informations and keep them even when your script is finished. Your results can now be saved in an external file. In these few lines, the variable loc contains the absolute path to the different folders of the tutorial and we define a function dump that will store the modifications of the dictionary. If you want to retrieve your modifications, you should call this function at the end of your scripts producing results.
Simplify the creation of a stored dictionary
In a single analysis, you might want to create multiple dictionaries and store them in an external file. This is the purpose of the python script routines/create_db.py which creates a file and adds the corresponding lines in the downloaded routines/Analysis.py. It's important to note that the script uses some flags specified as comments in the routines/Analysis.py, it won't work if you modify the flags. Anyway, I also specified an alias in the setup.sh, so once you have sourced the bash script and set up the environment, you should be able to create new stored dictionaries directly from the command line.
db foo
The last command will create a database/foo.pkl and add the load and dump lines in the routines/Analysis.py. You're welcome!
Templates
Now that we know how to store some python dictionaries and use them in different scripts, we can try to fill templates. This is done through the class Outfiles defined in routines/Analysis.py.
class Outfiles:
def __init__(self):
if not os.path.exists(loc.DATABASE+'outfiles_list.txt') :
f = open(loc.DATABASE+'outfiles_list.txt','w')
f.close()
lines = open(loc.DATABASE+'outfiles_list.txt').readlines()
self.files = {}
for l in lines :
toks = l.split()
self.files[toks[0]] = toks[1]
def writeline(self,name,text,clear=False):
self.write(name,text+"\n",clear)
def write(self,name,text,clear=False):
if clear : f = open(self.files[name],'w')
else : f = open(self.files[name],"a")
f.write(text)
f.close()
def fill_template(self,name,template,dic) :
tmp = open(loc.TEMPLATES+template)
out = tmp.read().format(**dic)
self.write(name,out,clear=True)
def create(self,name,filename=None,extension=".txt"):
if filename == None: filename = name
if "." not in filename : filename += extension
path = loc.TABLES + filename
self.files[name] = path
f = open(loc.DATABASE+'outfiles_list.txt','w')
for n,p in self.files.iteritems() :
f.write(n+" "+p)
outfiles = Outfiles()
Without going into details, the two functions you need are create and fill_template. The first one basically creates the output file, which can be a file of any format, and links it to a name (to simplify the use in python). The second, takes the output file and write the filled version of a template you specified earlier. In order to simplify the use of this class, I create a outfiles variable I can import in other python files.
Examples
Let's illustrate this powerful tool through 3 examples:
- Create a single template to fill two different text files.
- Fill various constants in a C++ header containing a namespace definition.
- Fill a Latex table automatically
1. One template two text files
We first define a template we want to fill.
# tables/templates/example1.tmp
This text is generated for the user {USER[NAME]} and his/her site is {USER[SITE]}.
This template requires a dictionary containing a key USER which is also a dictionary. In the file generate.py, we define and fill the different files.
from routines.Analysis import loc, db, dump, outfiles
# Example 1 : Fill 2 text files with one template.
# Template requirement: {USER[NAME]} and {USER[SITE]}
users = { 'Luca' : 'http://pluca.webnode.com/',
'Marko' : 'https://mstamenk.github.io',
# Fill here for your personal informations
}
db['USER'] = { 'NAME' : 'Luca',
'SITE' : users['Luca']}
outfiles.create('Luca','Luca','.txt')
outfiles.fill_template('Luca','example1.tmp',db)
db['USER'] = { 'NAME' : 'Marko',
'SITE' : users['Marko']}
outfiles.create('Marko','Marko','.txt')
outfiles.fill_template('Marko','example1.tmp',db)
Now by running the command from the root directory (be sure to use python2):
python generate.py
- We import the various variables we need from the
routines/Analysis.pyfile - In the database
dbvariable, we assign the values that will be fetched in the template - We create an output file, i.e.
tables/Luca.txtlinked to the nameLucain thedatabase/outfiles_list.txt. - We fill the file
Luca.txtwith freshly updated dictionarydbpassed to the templatetables/templates/example1.tmp. - We repeat the same procedure but create a file
Marko.txtusing the exact same template. - The files
tables/Luca.txtandtables/Marko.txtare now filled following the templatetables/templates/example1.tmp.
It's important to notice that we never used the function dump to save the dictionary in the database/db.pkl. It means that once the script is done, there will be no trace of the entries we did in an external file and you will not be able to retrieve them.
This simple example is meant to show you how easy it is to fill templates and create files from a python dictionary. Of course, let us now take a look at a more useful application to this automation.
2. Automated C++ headers containing namespaces
As every good python programmer, you use C++ to perform the time-consuming operations involved in your analysis. Let's say that during your analysis, you compute some important values that you will use again. It's easy to imagine that these values are related to some kind of parameters you set at the beginning. If you change the starting parameters, you expect your important values to be updated in the C++ namespace that you use. The straightforward way is to do it manually of course. This is probably also the less clever way and subject to artificial mistakes. Let's automate it.
// tables/tempaltes/example2.tmp
#ifndef ANALYSIS_H
#define ANALYSIS_H
namespace Analysis {{
double g({GRAVITY});
double m({MASS});
double h({HEIGHT});
double Epot({POTENTIAL});
}}
#endif
The template tables/templates/example2.tmp contains the code for a heading with a namespace in it where we can define the important values. Please notice that the python formatting language requires curly brackets to access to the dictionaries, for this reason, if the source code you are writing requires brackets, you need to double them. This is particularly annoying in Latex, but we'll come to that later. The next step is to fill the dictionaries in python.
# Example2 : C++ namespace
# In this script, only fill the db dictionary and save it to use later
db['GRAVITY'] = 9.81 # [m s^-2]
db['MASS'] = 80 # [kg]
db['HEIGHT'] = 20 # [m]
db['POTENTIAL'] = db['MASS'] * db['GRAVITY'] * db['HEIGHT'] # Epot = m*g*h
dump(db,'db.pkl')
# The next lines can be written in any other files since db is dumped
outfiles.create('Analysis','Analysis','.hpp')
outfiles.fill_template('Analysis','example2.tmp',db)
I don't think details are required here, the code is very simple to understand. Now the file tables/Analysis.hpp is fully functional and can be included in any C++ script.
A specific attention here is required because a C++ executable is a compiled object. Changing the header Analysis.hpp requires a new compilation. If you want to make it automatic, you can use the following two steps:
- Fill the template every time you import the file
routines/Analysis.py - Force the compilation each and every time you use the C++ executable, this can be achieved by using some control interface like Snakemake (see the tutorial).
3. Latex automated tables
The last example is meant to show you how to automatically fill Latex tables. This is my favourite way to use the automation. Filling data in tables is probably the most time-wasting step you have to do in an analysis. Especially when you changed some parameters and the values changed as well.
The output of the example is a latex table where we compute 3 different exponents of a constant, i.e.a=127.
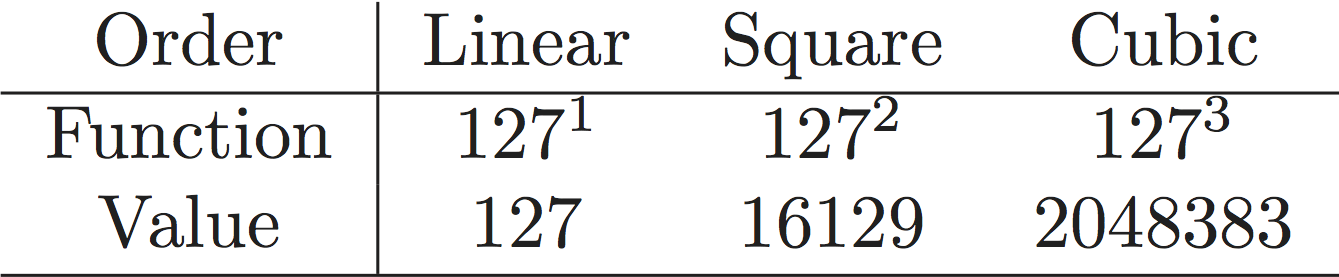
Let's look at the template:
% tables/templates/example3.tmp
\begin{{table}}[h]
\begin{{center}}
\begin{{tabular}}{{c|ccc}}
Order & Linear & Square & Cubic \\
\hline
Function & ${a}^1$ & ${a}^2$ & ${a}^3$ \\
Value & {first} & {second} & {third} \\
\hline
\end{{tabular}}
\end{{center}}
\end{{table}}
We just need to fill the script generate.py
# generate.py
# Example3 : Latex automated table
# Solve y=f(x)=a ^ x for first, second and third order
a = 127
db['first'] = a**1
db['second'] = a**2
db['third'] = a**3
db['a'] = a
dump(db,'db.pkl')
# The next lines can be written in any other files since db is dumped
outfiles.create('Latex','Latex','.tex')
outfiles.fill_template('Latex','example3.tmp',db)
That's it! Every time you compute your results in a python script, you are able to update them in the Latex tables without entering a single value manually!
Conclusion
The concept of Analysis Preservation is a very powerful tool. If done correctly, it will spare you tremendous amount of time. Remember, how you invest your time will determine the distance we have to run until the next scientific discovery or technological improvement! I hope you liked it, let me know via stamenkovim@gmail.com or Twitter. Thank you!